
Language-Agnostic Tooling
One of many challenges I struggle with working on Zed as one-person company is what to spend your time on. Should I just fix bugs? Write documentation? Brag about Zed features in blog post? Write features that make great demos to draw people in? Should I build payment systems to increase income?
Basically I have to ask myself: how can I optimize my user-happiness-increase/hour ratio?
As you may be aware I have a background in programming language engineering. I have some experience in writing programs that parse and statically analyze programs. At Cloud9 I worked on language intelligence features. At one point I spent a month or two (and my colleague quite a while more after) building a type inference engine for JavaScript. It's pretty difficult to do, but the result nice and allows for quite accurate code completion of methods and properties (try it out). However, building such a feature for one language takes a developer months.
This raises the question: should take the same approach for Zed? Should I spent months building a super accurate code completion engine for one language? That would mean that nothing much else gets done. Is that the best use of time?
I decided that, no, it's not. Instead, I started to think about create ways to have similar features in Zed, but built with much less effort.
Thus far I came up with a few examples of low-hanging language tooling fruit, if you will. They're much more pragmatic and often less accurate than their full-blown, expensive to develop alternatives (= custom implementations for each language). Nevertheless, I found them to very helpful and to have a good pay-off/hour spent ratio.
1. Symbol Indexing
This is the most obvious one: Zed's symbol indexing. Rather than writing complicated parsers for the languages Zed supports, I chose an ad-hoc approach with simple regular expressions. This is fast to develop, fast to execute and works reasonably accurately (depending on the language and regular expression).
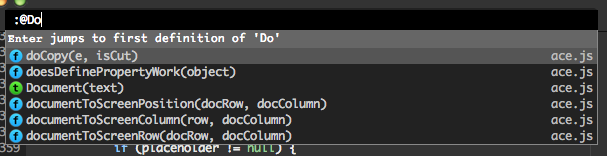
How it works is simple: for each language you have to write a function that takes source code and returns a list of symbols and their position in the file. This is how it worked for a long time. One JavaScript module with one indexing function per language mode. However, this could be further improved, because the pattern of these symbol indexers was always the same: define a few regular expressions, then run over the string to find matches and turn these into symbol info to return.
So recently I created a single generic Regex Indexer command, that can simply be configured for each language individually without having to write any JavaScript. For instance for Go:
commands: {
"Tools:Index": {
scriptUrl: "/default/command/regex_indexer.js",
inputs: {
text: true
},
regexes: [{
regex: "type\\s*([A-Z-a-z0-9_]+)",
symbolIndex: 1,
type: "type"
}, {
regex: "func\\s*(\\([^\\)]+\\))?\\s*([a-zA-Z0-9_\\-\\$]+\\s*\\([^\\)]*\\))",
symbolIndex: 2,
type: "function"
}]
}
}
Or Clojure:
commands: {
"Tools:Index": {
scriptUrl: "/default/command/regex_indexer.js",
inputs: {
text: true
},
regexes: [{
regex: "\\(defn-?\\s*([A-Z-a-z0-9_\\-]+)",
symbolIndex: 1,
type: "function"
}]
}
},
Regular expressions are still ugly beasts, but they work. And adding simple symbol indexing to any language is now often a matter of half an hour up to an hour (depending on your regex skills).
2. Bracket Checking
One nice feature of Zed is its built-in support for parsers and linters. For instance, Zed's JavaScript mode has JSHint built-in. JSON, PHP, Lua and CoffeeScript also have syntax checkers as part of their language mode, because there happen to be parsers for these languages written in JavaScript already, it's easy to integrate into Zed and showing markers for syntax errors inline saves you from one more trip to the terminal (or browser) and back.
That's all very nice, but there are many more language for which parser written in JavaScript are not yet available. And writing a high-quality parser for most languages is a lot of work.
So would it be possible to build some syntax tooling that helps at least a little in detecting common mistakes writing code?
One thing I've been experimenting with is my new bracket-check package (install via ZPM: gh:zefhemel/bracket-check). The name hints at what it does: it checks nesting of brackets: e.g. [{(. Is this a full-blown syntax check? No (although... almost for Lisps), but it helps.
Bracket-check's configuration file shows how to enable and configure it for various languages. You only have to configure two things: the bracket pairs to match and the parts to skip over (such as string literals, comments) etc. Here's the definition for Go:
go: {
commands: {
"Tools:Brackets:Check": {
scriptUrl: "./check.js",
internal: true,
inputs: {
text: true
},
brackets: ["()", "{}", "[]"],
skip: [["\"", "\""], ["`", "`"], ["//", "\n"], ["/*", "*/"]]
}
},
handlers: {
check: ["Tools:Brackets:Check"]
}
},
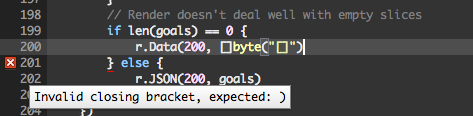
There are similar configurations for Clojure and Dart. More are trivial to add.
3. Property and Method Completion
The most interesting example (in my opinion) is my experimental follow complete package. Follow complete is based on a few observations:
- A lot of languages use a
a.banda.b()(and similar:a->banda->b(),a::b) notations for package namespacing, property access and method calling, e.g. JavaScript, Go, C++, PHP, Ruby, CoffeeScript, C#, Java, Dart, Groovy, Lua, Rust, Python, Scala etc. - Programmers tend to name variables of certain types the same all over the code base: e.g.
arrfor arrays,elfor HTML DOM elements. - Many languages use the
a.bpattern for namespacing, for instance in Python after youimport osyou call methods on it viaos.some_method(). Even without explicit imports,document.createElement()is an example of this in JavaScript.
If this is the case, wouldn't indexing any sequence of x.y, x.y(...), x(...).y and x(...).y(...) found in a code base, result in some useful completions when requesting code completion after typing x.? In that case, code completions could include y and y().
This is exactly what follow complete does. It uses Zed's new database APIs to index sequences of identifiers with .s in between and uses that for completion. As it turns out, if your code base is big enough, this gets surprisingly useful.
Again, here's a Go example. Go happens to use . as a package separator. Without any Go-specific knowledge, let alone knowledge of Go's APIs, Zed can now give the following completion for the datastore package (which is an Google App Engine specific package that is used fairly heavily in this particular project):
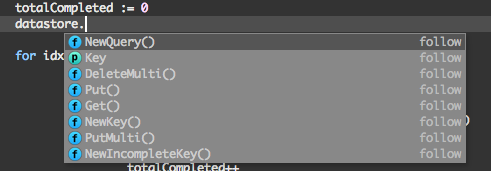
As you can see, although Zed "knows" that these are all methods, it doesn't show method argument names, simply because it doesn't know them. Potentially these method names could be matched with the symbol list, perhaps to also give argument names. Nevertheless, even without that getting some completion for APIs that are used in your project is quite useful.
If you want to try out follow complete as it is today, install the gh:zefhemel/follow-complete package, and after installing be sure to reindex your whole project with the Tools:Index Project command.
These are just three examples of useful language tooling features that are relatively language-agnostic. I'm constantly thinking about new ways to do this sort of stuff.
Any suggestions are welcome.
About Zed and this blog post
A little while back I announced I would make working on Zed my day-time job. Zed was open source before, and I kept it that way. In addition to the openness in code I also want to be open in design decisions and other lessons learned during this endeavor. This post is one example of that. Do you want to support me in working in this open way? Consider "buying" Zed.